Hello everyone! I’m experimenting with std::async, and although it may be working, it’s driving CPU way, way up, to the point where rack is nearly frozen.
Here’s my code:
std::future<bool> t1 = std::async(std::launch::async, &GrooveBox::processTrack, this, 0, &mix_left_output, &mix_right_output);
std::future<bool> t2 = std::async(std::launch::async, &GrooveBox::processTrack, this, 1, &mix_left_output, &mix_right_output);
std::future<bool> t3 = std::async(std::launch::async, &GrooveBox::processTrack, this, 2, &mix_left_output, &mix_right_output);
std::future<bool> t4 = std::async(std::launch::async, &GrooveBox::processTrack, this, 3, &mix_left_output, &mix_right_output);
std::future<bool> t5 = std::async(std::launch::async, &GrooveBox::processTrack, this, 4, &mix_left_output, &mix_right_output);
std::future<bool> t6 = std::async(std::launch::async, &GrooveBox::processTrack, this, 5, &mix_left_output, &mix_right_output);
std::future<bool> t7 = std::async(std::launch::async, &GrooveBox::processTrack, this, 6, &mix_left_output, &mix_right_output);
std::future<bool> t8 = std::async(std::launch::async, &GrooveBox::processTrack, this, 7, &mix_left_output, &mix_right_output);
// Wait for all functions to complete
t1.get();
t2.get();
t3.get();
t4.get();
t5.get();
t6.get();
t7.get();
and…
bool processTrack(unsigned int track_index, float *mix_left_output, float *mix_right_output)
{
// even if this function is empty, cpu goes nuts
return(true);
}
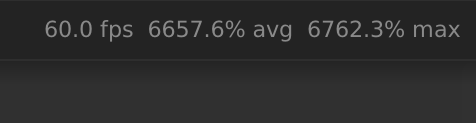
I also tried adding .wait() calls, like so:
std::future<bool> t1 = std::async(std::launch::async, &GrooveBox::processTrack, this, 0, &mix_left_output, &mix_right_output);
std::future<bool> t2 = std::async(std::launch::async, &GrooveBox::processTrack, this, 1, &mix_left_output, &mix_right_output);
std::future<bool> t3 = std::async(std::launch::async, &GrooveBox::processTrack, this, 2, &mix_left_output, &mix_right_output);
std::future<bool> t4 = std::async(std::launch::async, &GrooveBox::processTrack, this, 3, &mix_left_output, &mix_right_output);
std::future<bool> t5 = std::async(std::launch::async, &GrooveBox::processTrack, this, 4, &mix_left_output, &mix_right_output);
std::future<bool> t6 = std::async(std::launch::async, &GrooveBox::processTrack, this, 5, &mix_left_output, &mix_right_output);
std::future<bool> t7 = std::async(std::launch::async, &GrooveBox::processTrack, this, 6, &mix_left_output, &mix_right_output);
std::future<bool> t8 = std::async(std::launch::async, &GrooveBox::processTrack, this, 7, &mix_left_output, &mix_right_output);
t1.wait();
t2.wait();
t3.wait();
t4.wait();
t5.wait();
t6.wait();
t7.wait();
t8.wait();
// Wait for all functions to complete
t1.get();
t2.get();
t3.get();
t4.get();
t5.get();
t6.get();
t7.get();
This is my first time playing with std::async. Any suggestions? Thanks! ![]()