I spent a ton of time trying to figure out why a sine oscillator I made using a lookup table suddenly had a bunch of irregularities in it and realized that it came down to an issue involving simd::ifelse() that I don’t understand.
Right now I have two separate implementations for processing the signal as an LFO, which doesn’t currently implement oscillator sync, and as a VCO, which does. I was going to go back and decide what I wanted to do with the oscillator sync for the LFO after I applied it to the VCO. In my plugins, I’m making LFO and VCO the same but including a switch that basically just updates the paramQuantity for the frequency knob.
Anyway, my original code was:
float_4 sine = simd::ifelse(freqRange == VCO, oscillator.process(args.sampleTime, sync), oscillator.processLFO(args.sampleTime));
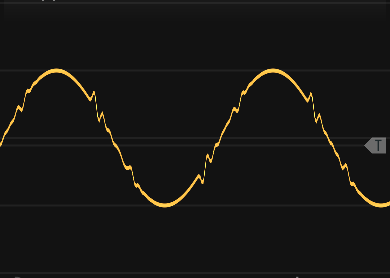
But I noticed I was getting a sine wave that looked like this:
So I commented out everything to do with oscillator sync and then at some point realized “oh, now the code is exactly the same for both functions.” The LFO was perfectly smooth when the VCO, at the same frequency, looked like the picture, even when the functions were the same.
I tried taking out the ifelse and both of the waveforms were perfectly smooth for both functions (a bit redundant because they were the same internally, but I had to make sure).
Then when I tried float_4 sine = (freqRange == VCO) ? oscillator.process(args.sampleTime, sync) : oscillator.processLFO(args.sampleTime);
Bam, no more irregularities. What is my use of simd::ifelse doing that causes this?
The simd if else is not a ternary operator with short-circuiting, is the short version.
inline float_4 ifelse(float_4 mask, float_4 a, float_4 b) {
return (a & mask) | andnot(mask, b);
}
so both a and b get evaluated at all simd points and then the unused values get masked off
This is basically how vector-conditionals work. This is made more confusing by immediately above having
inline float ifelse(bool cond, float a, float b) {
return cond ? a : b;
}
which is by no means the same statement
For instance the float if else will work fine in a form float *x = nullptr; ifelse(true, 0.,f, *x) whereas the simd equivalent will crash.
The basic reason for this is the SSE instruction set (which rack::simd is making it so you don’t have to see, for better in many cases, but perhaps not in this one) implements if essentially as masks. You get functions like _mm_cmpgt(a,b) which does a parallel comparison of a and b element wise in 3 of 4 instructions and returns a mask which you then and or or on for the result, so you can have different truthiness across your vector. But as a result you don’t get short-circuiting since that’s not consistent with a single vector pipeline.
My guess is your .process method updates an internal state so the short circuited version implements one-or-the-other state but the non-short circuited version updates both (since its not short circuited) hence the difference you see.
The conditional move part is SIMD is indeed vexing. I have a few links that might help.
My demo VCO has a very simple simd sineVCO. Take a look here
In my own work I use my own wrappers around the rack::simd stuff to try and avoid my own confusion about this stuff. It’s all in one file, and the key is here
Lastly, in the library under Squinky Labs is my BasicVCO. It has two sines: one uses a simd approximation, the other uses a lookup table.
All my VCO code is basically copied from the VCV Fundamental VCO.
The ugliest thing I’ve had to do so far is an LFSR in SIMD. That was horrible because all of these bitwise operations are so easy on an unsigned 32 bit integer, but when you start having to deal with masks, it gets nasty.
I implemented an LFSR in SIMD. It’s documented here:
The trick I found was to turn my register around end-to-end. Instead of shifting bits down towards the least significant end, which most implementations seem to do, I shifted up, which means that a comparison less than 0 gives you the truth value of the msb in a single operation.