After multiple days of refactoring app/* widgets, I now consider them “modernized” enough to move on, and I believe all undo history actions are now implemented. Until the release, testers may discover crashes or missed history actions, so post an issue if this happens to you in the v1 branch.
2 Likes
Added module bypassing, by context menu or Ctrl/Cmd-E.
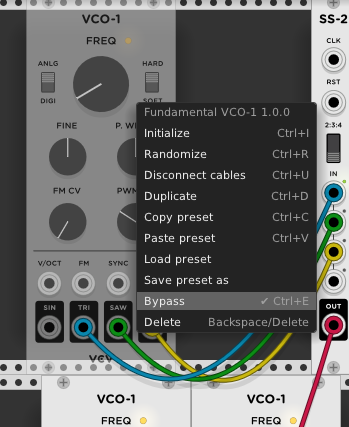
This was actually added a couple weeks ago, right before I started this “blog”, so I’m mentioning it now.
13 Likes
Does this have passthrough (ex. bypassing signal → LPF → signal just copies non-filtered audio) or shush the module entirely?
This is a standard case. Signal will be passed to the next module in the row without any effects by module in bypassed state.
I have another question, @Vortico. Maybe in the future you will be able to add the ability to freeze modules so that they do not take away cpu resources? Or combine this function with bypassing somehow, idk.
Is the new right-click behavior finalized?
I honestly like the old behavior of the right-click (initialize parameter value) better than the current v1 behavior, where right-click opens the menu and requires another click to reinitialize.
I think the following behavior is more intuitive for performance: Shift right-click opens the context menu to enter a value (or click reinit menu item). Just right-click should reset the value as before.
I find myself using the current right-click reinit often when playing Rack live where I reset the parameter value as part of the performance, e.g. quickly resetting an attenuverter. I think it is way more convenient to do that with one click instead of two or having to use the Shift key in addition.
5 Likes
I don’t feel that initializing a parameter is something that deserves the first-class right-click assignment. Initialization isn’t even a concept in hardware modular. I believe that once we get used to this, we won’t think twice about it, as the quickly-openable context menu will contain many more options in the future, such as Unmap (for MIDI mapping) and a detailed label of which CC# or perhaps which VST parameter is controlling the parameter.
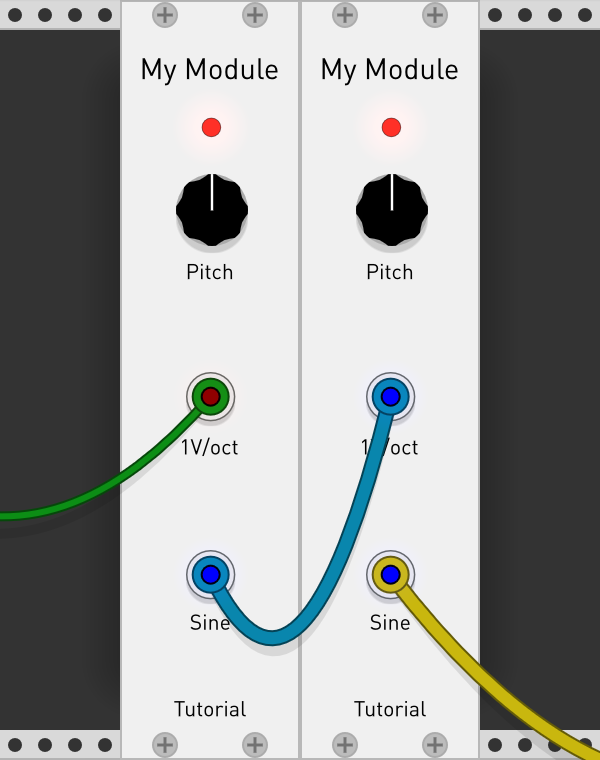
Finished polyphony. I ask all developers who are interested in adding polyphony to their plugins to take a look at the new Port methods at Rack/include/engine/Port.hpp at v1 · VCVRack/Rack · GitHub.
13 Likes
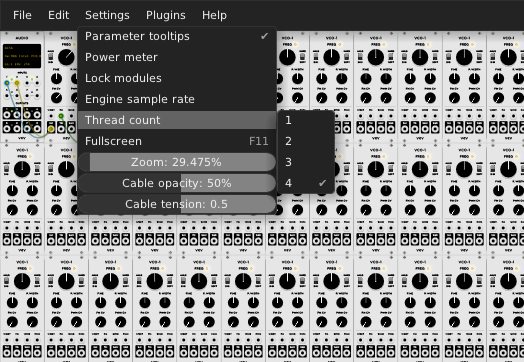
Added multithreading. Best results when the thread count is set to the number of physical cores of your processor. You may use more to take advance of hyperthreading, but performance is worse with all of my tested devices. Diminishing returns for increased thread counts.
46 Likes
I would give this so many more hearts if I could. Thank you!!!
2 Likes
why not add auto detect option by default?
Could you explain a little bit more what you have done here Andrew? I’m afraid looking at the commits doesn’t help a non-coder much (but it doesn’t seem like you have had to add a lot of code to enable this).
Are you saying that it will be OK (/desirable) to set the number of threads to the number of cores as a Rack default? Or that one should only increase them incrementally as one needs more modules in a patch?
Is there any overhead to setting more threads than needed in a patch (additional CPU/heat), that is, are the extra threads sleeping if not in use or are they looping and waiting for instructions? Or is it the other way round, that modules will be allocated to additional threads before one thread is ‘full’, so to speak, such that no one thread will be heavily loaded even on smaller patches?
(Sorry, I know all that betrays my lack of understanding of how all this works, and if replying please assume you are addressing an imbecile !).
There’s always memory requirements to having more threads than not. (Slightly less of a big deal now than ten years ago though.)
It will default to 1. No detection needed, except for setting the maximum number of threads to the number of logical cores.
I wrapped module stepping in an OpenMP parallel for. Pretty basic, but it does exactly what it needs and I can’t get any better with custom threading code, so might as well keep it simple. @JimT’s fork used spin locks on worker threads, and this is exactly what the OpenMP implementation does but in one line of code.
Yes, as always when parallelizing things. I mentioned in the original post that there are diminishing returns. And yes, the implementation uses spin locks. On my dual-core laptop I’m typing this on, each thread spends 30% of the time spinning and the rest of the time stepping modules.
1 Like
Forget about memory. Rack uses 100MB on a large patch (which is nothing when you have >=8GB RAM), and each additional thread takes maybe 100KB.
2 Likes
Thanks Andrew. A bit more research done and I think I understand all that - don’t add threads unless you need them (as was the case with JimT’s fork).
Will the remaining mS indication work OK with extra cores enabled? Can Amdahl’s law be used in calculating that (though I understand that it is idealised)?
In Rack v1, μs (microseconds) are displayed instead of mS (millisamples) so that the measurement is sample rate invariant. This also means that using multiple cores will not total to 100%, but perhaps 130-150% with 2 threads for example.
4 Likes
Sort of. As far as I understand Amdahl’s law its mostly concerned with calculating the total speedup gained by shrinking the amount of time that is spent on the things being sped up, while the rest of a system is considered a fixed expense. So basically a 50% speed boost on something that happens 1% of the time is actually a net gain of 1.005 while a 10% improvement on something happening 80% of the time is an improvement of 1.08. Although since it’s a fork-rejoin type situation, it can’t ever be faster than the slowest single module; even if there were infinite cores you still have to wait for them all to sync up to maintain lockstep.
1 Like
Amdahls law is actually not that relevant here, but the overhead of locking (that isn’t needed for serial) is.
A clipping bounding box is now used in draw() calls, to prevent drawing offscreen widgets and modules in the rack and module browser interface. This allows tens of thousands of modules to be searched in the module browser without lag and reduces CPU usage overall. However, an API change was made in Widget::draw(). A regex was added to https://vcvrack.com/manual/Migrate1.html for automatically changing your source code.
1 Like