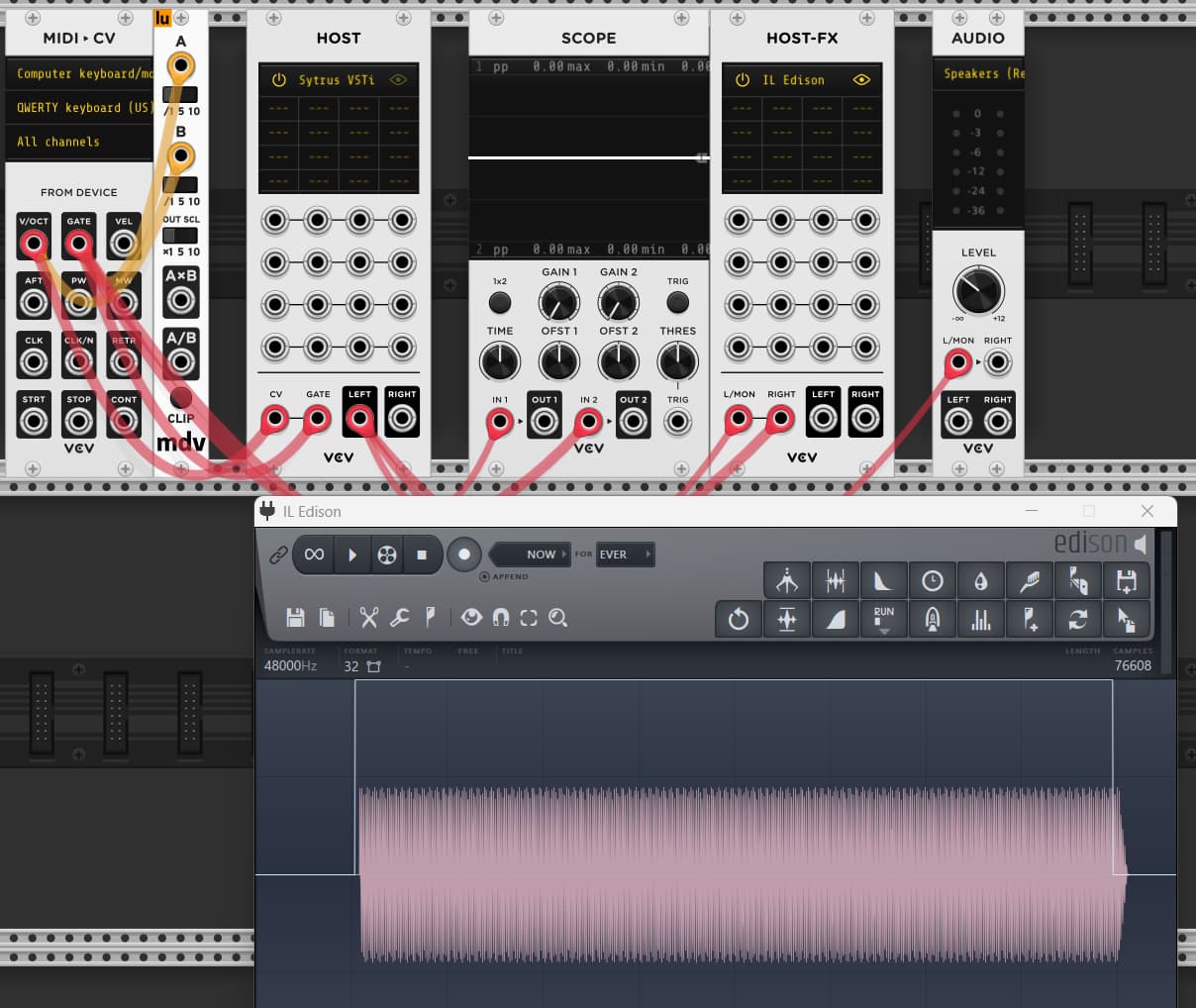
I always wondered how process per block works in Rack (in case of VST, for example). Since the environment is process per sample, does it first accumulate samples, than release it? Somethings like this?
struct BlockModule : Module {
static constexpr int BLOCK_SIZE = 16;
float blockBuffer[BLOCK_SIZE] = {};
int writeIndex = 0;
int readIndex = 0;
bool blockReady = false;
void process(const ProcessArgs &args) override {
blockBuffer[writeIndex++] = inputs[IN_INPUT].getVoltage();
if (writeIndex >= BLOCK_SIZE) {
processBlock(blockBuffer, BLOCK_SIZE);
writeIndex = 0;
readIndex = 0;
blockReady = true;
}
if (blockReady) {
outputs[OUT_OUTPUT].setVoltage(blockBuffer[readIndex++]);
if (readIndex >= BLOCK_SIZE) {
blockReady = false;
}
} else {
outputs[OUT_OUTPUT].setVoltage(0.0f);
}
}
void processBlock(float* block, int size) {
// example
for (int i = 0; i < size; i++) {
block[i] *= 2.0f;
}
}
};
If so, and the block is “huge” (usually, for VST, 256 sample), this means that when I trigger a VST inside Rack, it starts with a delay of buffer-size (i.e. 256 samples)?
Is that correct?
(which is what seems to happens capturing some audio, notice the trigger signal before audio…):
In fact on VST/DAW in general, I never noticed that different stream are “unaligned”. In fact, as you can see, Rack treat process per block differently as for process per sample, due to the fact that it accumulate/than output (per block) instead of output immediately per single sample
Look at the gate (per sample): its 256 samples ahead the process per block. So in this terms Rack its a sort of “un-sync” with plug that need buffer to be processed.
I heard that, but I keep wondering how that’s going to work. Whenever there is feedback cabling across a module or a chain of modules I don’t see how this could be done without processing it one sample a a time. So there will have to be a clever algorithm to determine where block processing is possible and where not. But I am sure Andrew is aware of this and will find a solution.
Where block processing is possible, it could improve performance by making better use of CPU caches.
In Rack 3, modules can set power-of-2 minimum and maximum block sizes. Modules ported from Rack 2 will have min = max = 1 until the developer changes it. For example, an FFT convolution reverb might set min = 16, max = 1024. Virtual circuit modules like VCV VCF could set min = 1, max = 1024 and process samples in a fast loop.
Newly created cables will have 0-sample latency, unless adding one creates a feedback loop. In this case, the cable will use the greatest minimum block size in the module feedback group. This latency is shown on the port tooltip.
Rack 3’s engine scheduler organizes the patch’s graph topology into an ordered queue with dependencies, so the entire audio input buffer can be processed one module at a time in signal chain order, in parallel by multiple threads if possible. Feedback groups are processed as an atomic “task” by a thread, where the feedback latency is minimized based on the allowed block sizes of the modules.
Amazing, @Vortico, thanks. I’ve been hoping that some version of that design would be implemented for a long time. Really awesome stuff on multiple levels.
Thanks for the info, Andrew. I like that approach. One question, will it be possible via the left and right neighbor pointers to get a full buffer of audio data from an expander module (not talking about the messaging, but direct access)?
You can do that today but if you do, then you own all multithreading synchronization issues.
Think about it. If you have direct access to another module’s buffer without a mutex, then how do you know whether that buffer reflects the last frame, the current frame, or some intermediate in-progress state changing on another thread running concurrently?
The message passing expander mechanism is what gives you that synchronization and thread safety. If you cook your own, then you probably end up with the equivalent.
If you don’t override process in the expander, there is no other thread doing anything with buffers or other properties within the same frame (except for the UI thread as always). It is perfectly fine doing it this way in Rack v2.
The documentation states explicitly that you can safely access parameters, lights, input and outputs of expander modules from your process() method. Basically these are all updated before the process() functions for all modules are called. So the only possible interference is by the other module’s process() function, which as stoermelder said, you normally have under your own control.
That is what I meant by having it under your own control. Direct access to expanders requires that you have the class definitions, so they are usually your own. If you access their elements,you wouldn’t do anything unsafe in their process() functions.
If all you are accessing is lights, inputs, and parameters, you don’t need the other modules’ class definition at all: you’re dealing entirely in universal VCV classes.
I just never accessed an expander that I did’t write myself, but in theory I could and then all bets would be off what happens between two process() functions.
Unfortunately the expander API will need to be reworked, possibly in an API-breaking way. In Rack 2 there are two ways to communicate with neighbor modules: read/write their params and ports, or read/write their double buffer that is flipped after each frame. Neither is compatible with block processing, so I need to add a new way for your module to announce that it is connecting to neighbors in an event handler.
While you’re doing that, some of us have been discovering that we have a need to connect modules that are not adjacent. It would be nice to have extender functionality that isn’t dependent on adjacency. After all, in a physically skiff, backplane connections don’t have to be between adjacent modules.
This brings in the idea some (including me) have floated before:
Data cables that would carry messages instead of CV. With a common message header, we could have cross-plugin interop with a content-type field containing the id of a registered message format (register a descriptive text, get an id, for compact messages).
Then we could pass audio/cv blocks, OSC, param sets, text, json, midi1, midi2, colors, and other data that devs can agree on. Of course, you could also register your plugin or module slug for “private” messages. This could even be the same protocol for extender message passing, which becomes just a hidden data cable always present between adjacent modules.