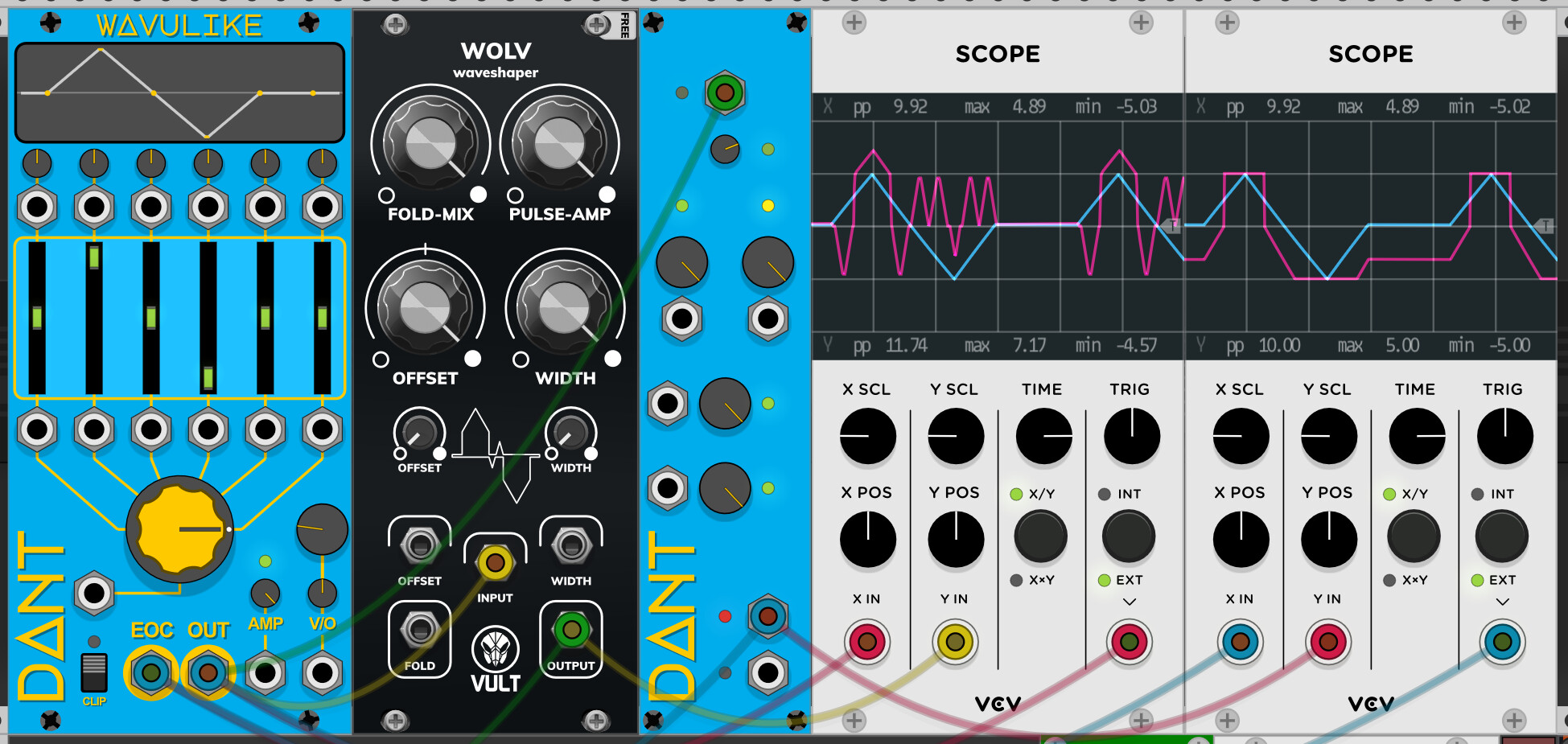
But, occasionally I post longer bits to my YouTube, so I figured I would create a thread for them, since my sub count is literally 3 right now and the algorithm hates my content
Yes, free modules, but not open source, currently the path of least resistance for me given my day job. But happy to answer questions on the theory or design of my modules.
Not sure yet, the phase correlation meter uses quite a lot of CPU, and trying to decide if the waveshaper needs some extra “spice”, but I do have next week off work, so maybe by the end I will have an update close to being ready
Thanks Dan, is there a way to lessen this ‘phase correlation meter uses quite a lot of CPU’ ? Maybe Squinky Labs could your man to ask about that.
When it’s ready it’s ready, I’ll see what damage I can do to my sounds.
My XF-xxx crossfaders do signal correlation calculations using pipeline accumulators. So they work on a moving window and only need to work with one sample at a time. I don’t know if there’s anything there you might be able to apply to your needs?
To be honest, I am still very much a C++ novice and my understanding of the correlation calculation is limited. I believe I have implemented a moving window of 512 samples, which I then accumulate to pump into the correlation calculation. So in one sense, it is only working one sample at a time, but in another sense, I am accumulating the value of 5 different variables each sample.
The CPU use may be acceptable, but almost certainly there is a way to improve my implementation.
You can see from the screenshot that my waveshaper uses very little CPU, because it strictly does only operate on the current sample, and it does simple calculations.
I am guessing that std::sqrt is a potential bottleneck, and there is probably a better/more efficient data structure than the basic array, but I haven’t had the time to instrument my code for profiling yet, so wouldn’t like to guess at optimizations.
Also, I ideally wanted to have a way to make the buffer size variable, but not sure that’s really possible with my current implementation
Hmmm, I just realised that about a week ago I was testing out the Vult Wolv module.
I totally forgot about this, but it must have unconsciously influenced my experimental waveshaper module.
I just checked it out though, and our algorithms are different enough I think that my module will still have value. But this is what I was meaning about needing to add some “spice” to the waveshaper, I want to ensure that it does something interesting.
I may be off base, but looking at your post I think the issue is that for every sample you are doing std::accumulate of the entire bufferSize of samples. Submarine was talking about doing a running window so that for each sample you only need to look at that one. Maybe he can provide more info.
Sure sqrt isn’t super fast, but you are only doing one, so I think you could get away with that. There is a more efficient approximation in the plugin sdk I think, but not sure.
I think the issue is that for every sample you are doing std::accumulate of the entire bufferSize of samples
Yes, I can see how using the std::accumulate for 5 different arrays of 512 items could be a bottleneck. Any suggestions there?
The correlation equation I am using is really a statistical correlation, rather than being specifically for signals or waveforms.
My understanding is that it is calculating the correlation between X & Y throughout the window, that is why I am summing the whole buffer, and also why I want a variable buffer size.
For an LFO a longer buffer would be able to more accurately calculate the correlation of the longer wavelength, where as for high frequency signals, a shorter buffer would perform better.
The window size has some relationship to the wavelength, at least in my intention it does.
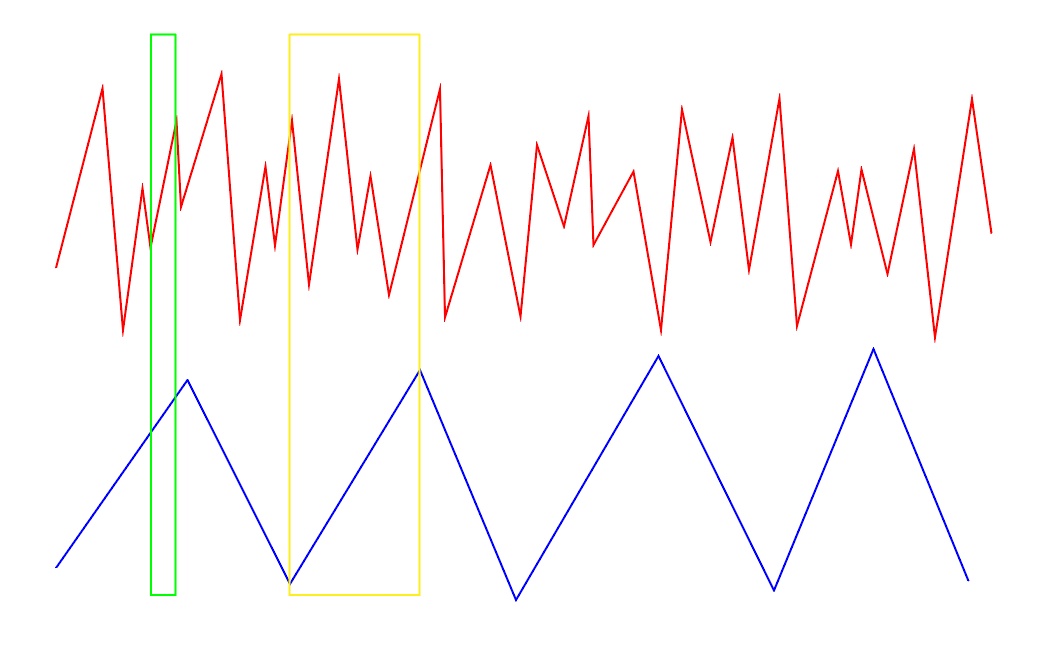
For example in this crude diagram, the correlation between the top and bottom signals is fairly obvious in the green window, but what is the correlation in the yellow window?
I don’t currently understand how you could calculate the correlation using one sample, unless that correlation was literally the difference between the two signals at that single sample.
Read @carbon14 's post and ask him for a code example
Yep, will do once I get some more time to work on things
Also, by the way, when I was researching phase correlation, I did read that typically for audio signals, phase correlation meters use a window of 50ms to 100ms, that is why I chose the 512 buffer length as my array size.
But obviously the key part there is “audio” signals, and the typical use of a phase correlation meter would be on signals that are identical or very similar but slightly out of phase, rather than my more experimental usage, to generate a CV where the two signals can be totally unrelated (thus generating interesting correlation patterns).