I find it fascinating that despite all my efforts no chatbot (i.e. ChatGPT, Gemini, Claude) could provide me a proper VCV Rack patch.
It’s pretty simple to select all modules and copy the relevant JSON into their chatbox but whenever I ask for a nice melody or some smart cable arrangement they return something useless.
They typically recognize the modules and suggest some basic module arrangement (like LFO → ADSR → VCO → VCA → VCF → output) but when I ask for a modified JSON code the result is disappointing.
Do any of you have a better experience with this technique?
It’s funny, I was thinking about how it would be possible to write a program to generate a VCV Rack patch, because it is really just a compressed file with some JSON text inside it. Now, how to make a useful or interesting patch, or even a patch that works at all, would require a lot more thought. I imagined making some kind of software library for programs to generate patches.
As to why LLM systems aren’t good at coming up with patches, I believe it’s a combination of lack of good training data, and that the problem domain does not match the kinds of semantic patterns present in source code or written human languages.
Structurally sound module arrangements and such (for some sort of synthesizer topology, for example) should be possible relatively easily; “asking for a nice melody” is something that might require some more creative prompting, hehe.
I’ve experimented with this in various ways, one example: I discussed with Microsoft Copilot about a custom plaintext format for musical notation, and established a sort of pseudo-MIDI-event format in CSV. Then, I proceeded to chat about a Python program that conveniently converts that plaintext to actual MIDI files. All of this went perfectly, and Copilot could then output musical “ideas” and melodies, even harmonies with multiple voices, directly as text, and I just ran those through the Python script and listened to that stuff in a DAW.
HOWEVER all of the actual musical content was more like… humorous, and entertaining, but it wasn’t actually capable of outputting an actually “wow, hey that’s nice” level of melody or something like that. Even with more advanced prompting (recognizing the way language models work, and that the custom format can undermine possibilities for desired kinds of statistical chains to happen, within the actual textual context window, that would lead to nice musical output, and mitigating this by trying to ask for a more common representation of musical content first - but nah, the results were more like funny, not seriously musical :)).
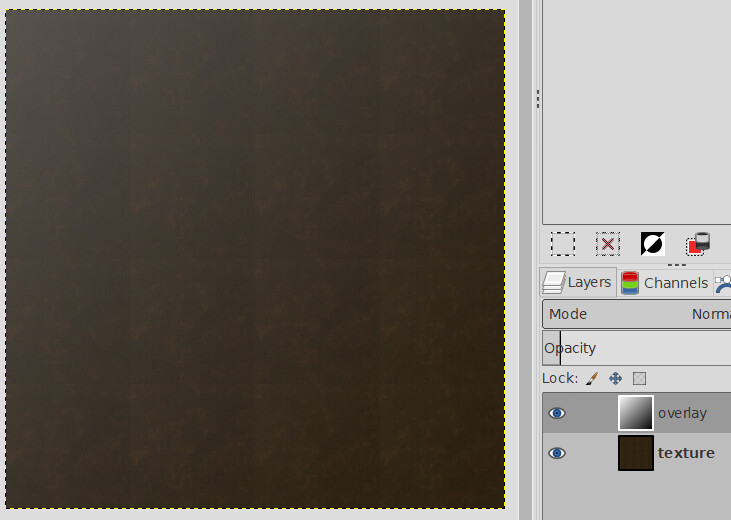
for a seamless texture the image should be split into the texture part with even distributed lightning, and a transparent overlay that covers the whole area providing a smooth gradient:
That’s a nice technique to overlay a gradient for the lighting falloff. I love the worn edges of the masonite panel and corroded screws, so I’d want a way to bring these elements back in. An improvement for the screws would be to have a number of them with the slots at different angles, but a consistent lighting angle.
The conversation mode of MJ doesn’t seem quite as good as your Chat GTP one, it takes what you say and reinterprets the prompt, rather than actually making direct edits to the image…
I doubled checked a few times… I am allowed to share this on social media (does this forum count as social?) and I am encouraged to tag it with @labsdotgoogle