Sure, though fair warning, it is not simple or easy:
Note that text-to-image is just one of many modes available in Visions of Chaos, you can just download the app and play with everything that is not under the machine learning section and still have a great time
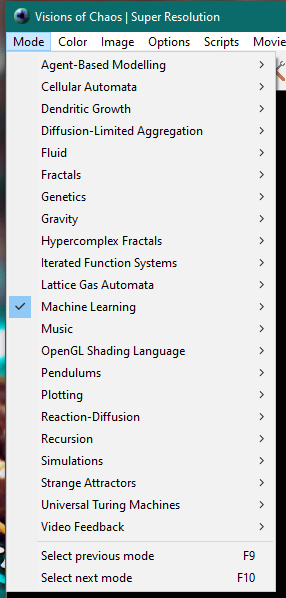
Now, specifically for the machine learning modes, there is a lot of pre requisites, you need an Nvidia RTX 20x or 30x GPU and then you must following these instructions for installing everything Softology - Visions of Chaos - Machine Learning Support
Once you have all that stuff installed, you need to activate one of the machine learning modes, then the app will prompt you to download all the models, I think currently there are 51 different models, each one can be multiple GB, these step was the hardest part, because the download can be a little bit flaky.
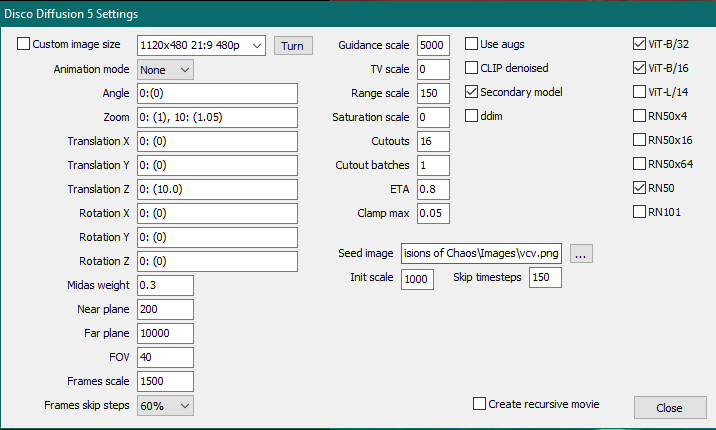
If you get all the models downloaded, then finally you can start generating images, my advice for that is to start really simple and at small resolutions, change one thing at a time and re-render, this way you will start to understand what each parameter affects
If you get stuck but want to persist, the author of the app has a discord and he is very active and responsive there
An alternative is to use something called Google CoLab, this is a cloud based virtual machine solution for running machine learning notebooks shared by other people, though this is just as complex, if not more so, and to really get the best benefit you would need a subscription to the pro version, but i’ll leave this tutorial in case thats of interest https://youtu.be/FA2MNG8D5x0