Yes, your modules seem pretty well behaved. very nice. 
Users can’t change the implementation of a module with a menu item though. It’s up to me and the users’ choice to improve what we can without touching the code of modules.
For sure, and I’m super excited about all the V1 improvements, including the new multi-threaded engine. It’s going to really help people. I only meant to point out that module devs aren’t off the hook by any means. And that the variability in plugin performance is often larger than the possible gains that threading can give. But by no means did I mean to slight how great the multi-threading is!
just want to say that in no way do I dismiss the idea of efficient software. we have limited resources in vcv rack, we shouldn’t waste them. since our resources are so limited, I felt we should also make use of all the resources available.
we shouldn’t waste resources. we shouldn’t limit people to a fraction of the resources they have available.
it’s hard to get across every aspect of what we mean in discussion, especially when we’re concentrating on a single aspect at that moment. for example, in the statement above I also recognise that limiting resources can be a huge creative boost. also that adding multi threading might not actually do very much when adding the 7th thread even if you have 24 real cores.
I also recognise that there are other things the vcv engine can do to make more resources available that might be as effective as multi threading. I’ve been playing with one and the effect is as profound as adding 6 threads to my patch, adding extra threads on top then works as before.
we also shouldn’t lose sight of the fact that modules are, by nature going to require resources, and better sound processing is going to need more resources by its very nature. we’re working in a hard realtime limit where every sample must be completed within a sample time. but when working on a single thread, you have to leave room for the entire rest of the patch to run as well.
but of course some modules can do their own multi threading to break that. but that’s extra complexity and latency in their code that might not be desirable.
this isn’t everything I’ve got to say about modules and resources either. when I try to say all this the discussion gets unfocussed, long, and hard to follow. imagine all the branching points in discussion from this comment now 
Perhaps slightly off topic but are there any well known cpu hogs?
Well, people grumble about it, but they are usually too polite to flat-out criticize someone’s work. If you watch some of Norbert’s videos where he does capsule reviews of huge numbers of plugins he will call that out sometime.
This conversation has “inspired” me to finish a doc I’ve been puttering with since last July. I’ll go make a post for it up top. https://github.com/squinkylabs/SquinkyVCV/blob/master/docs/efficient-plugins.md
4 Likes
portland weather
1 Like
This one is a huge pain to try and deal with. Sometimes branching around code is entirely worth it, sometimes not. Does anyone know what the best practice is here for instrumenting branch overhead? I’ve heard cachegrind can help but even with cachegrind’s aid there are many CPUs out there.
Yes, Portland weather is a “pig”, but it seems mostly it’s because it does so much, not because it’s poorly written. I think it would be a lot of work to make that 4X more efficient 
Here is a summary of what I read above and some thoughts of mine:
- Parallelization is very promising: Linear(ish) performance gains have been demonstrated + the potential of modern CPUs can only be used that way.
- Optimization of algorithms can be very beneficial but it is hard to to make predictions here.
My thoughts:
- Parallelization vs optimization: Both should be addressed separately because they promise separate performance gains that add synergistically.
- Parallelization is imho essential. This is what modern CPUs are designed for. Assume someone has a system with an 18 core CPU (nothing unusual in the near future), and Rack can at best only use 5.6% of the power of this CPU. Obviously, you can’t do that… I remember trying hard to convince the developer of Hauptwerk (a pipe organ specific sample player) to add support for ASIO drivers back in 2004. Nowadays, the idea of not supporting ASIO in a standalone sample player is rediculous. In this case, I feel that in 15 years people might again say ‘how could you even consider not using most of the CPUs potential back then?’
- Optimization of algorithms is the responsibility of module developers. A usually complex task to be carried out by a large number of people with their individual backgrounds. I feel that this calls for a methodology. In my experience, the pareto principle applies here: Some optimizations can be very beneficial while others waste lots of time with little benefit. My suggestion would be to come up with a kind of optimization guide that encourages or discourages certain practices that are typically responsible for good/bad performance. For instance: Use (high resolution) lookup tables as a replacement for expensive function calls, avoid per-sample calculation of data that is only required every n samples etc.
Summary (of my opinion):
- Parallelization: Unavoidable. Multi core support is a key feature.
- Optimization: Come up with something like the ‘10 commandments for good performance’, addressing the top optimization opportunities, each with a short explanation, a ‘bad’ and ‘good’ code example. Maybe plus a short introduction to performance analysis (including suggested tools, references to guides etc.).
1 Like
i know, and i was not at all suggesting it was poorly written. i was simply giving an answer to the “known cpu hog” question.
One very simple optimization for VCV rack (and similar single thread applications) is to disable hyperthreading if intel and the equivalent for AMD. By splitting up the core it reduces your single thread performance by (changed from my original 50% estimate to TBD %)… no need for that! turn that crap off and get a real dedicated core.
I think that’s a bit misleading. If you have N active threads and N physical cores, the OS allocates each one to their own physical core. With simultanious multithreading, if you have N+1 threads, two threads will run at perhaps 50-70% efficiency (averaged over 1 ms, say). But without simultanious multithreading, the OS will switch between them so that each thread runs 50% of the time within that 1 ms window.
So simultanious multithreading is worth it unless those >N threads are solving the same problem that is sublinear in parallel speedup.
Andrew,
I’m using a Fortran compiled program with sparse matrix it is almost 50% improvement in speed to turn off Hyperthreading. however, I’m not sure with less cores and lest pure 100% burried workloads how it handles that. I fully believe what you are saying and I think its worth a go since its only two clicks and a reboot.
In many cases that’s true. In the case of VCV modules it is not true. They are simple to optimize. And I say that from having done it many times. almost any module can be sped up by at least X4 my just removing calls to sin and cos and replacing them with something fast.
Idea: Write a header file with functions like
/** Padé approximant of order M/N of sin() with polynomials written in Estrin's scheme. */
template <int M, int N, typename T>
T sin_pade_estrin(T);
etc. with names and docstrings explaining exactly how they approximate the function. I’ve been meaning to do this for a year but haven’t had the time. If you release it under CC0, I’ll adopt it into Rack’s DSP library.
2 Likes
Oh, that would be great! Unfortunately I don’t so mine that way - I have a function that takes a lamba and generates a lookup table with first order interpolation. So it’s all jumbled up with my other source code, and the peculiar way I do things. I do remember talking to someone who was going to do a fast trig approx, but I don’t know if they ever did.
If you have access to Mathematica, or know how to use SymPy (I don’t), generating custom approximations is real easy.
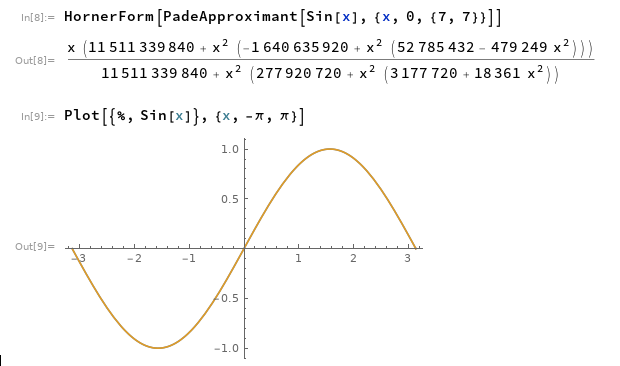
A good symbolic regression toolkit will do it too. Eureqa was the easiest (although they’re moving heavily cloud+subscription, not sure if the personal desktop version is still around) since you just threw a spreadsheet at it and waited for it to crunch.