Noob question but - are there great, most-accurate, pre-computed lookup tables for these floating around somewhere in the ether? And secondly, for polyphony, can this not be combined with SIMD for even more bang-buck?
Theres’s a fork of FastTrigo here that does exactly that (this commit), plus some cleanup, and thus supports Linux as well:
@Vega@Squinky@LarsBjerregaard Now I compiled and ran my version on Linux on the same machine I measured under Windows. On Linux there’s nearly no performance improvement using the VCV Rack performance meter. Maybe I’m wrong but it seems that GCC on Linux does more optimisations out of the box than GCC under MinGW64 on Windows. What do you think?
Well… I have always used an interpolating lookup for more accurate results, and to avoid “stair steps” when I don’t use huge tables. The one I use I wrote 25 years ago, and ported to VST 15 years ago, and ported to VCV like 3 years ago. I don’t use any “pre calculated” tables, I generate them all the the module is instantiated, and I can generate them for any arbitrary function. So, pre-simd, I used them for all sin, cod, exp, log, tanh, etc…
It wouldn’t really be practical to have pre computed tables, and there are so many choices, primarily how big to make the tables. And it’s so easy anyway, not like those fancy approximation that are less easy to write.
FWIW I usually would make a single table and share it between all my modules that used it. So, for example, only one copy of the generated lookup for all the Chebyshev, Functional VCO, etc…
Towards the end of Squinky Labs I was using a lot of SIMD to make poly fast, as you mention. So I did start to use the VCV library simd for most trig functions and exponential. But I still used lookup tables where it was easier or better. So Comp and Comp II used a lookup for the gain control functions. These are pretty complicated, with the usual log/anti-log for the gain, plus a cubic spline for the soft knee, rather than the common (and worse) second order polynomial. That allows the gain control to be C1 continuous, and hopefully to sound better. It seemed way too hard to do a SIMD approximation of that, so in the comps I use SIMD for the amplitude detector and VCA, but use a lookup table for the gain control. But it’s still mostly SIMD, and quite fast.
For reference, here is the code that Squinky Labs modules use to create a sine lookup:
template <typename T>
std::shared_ptr<LookupTableParams<T>> ObjectCache<T>::getSinLookup()
{
std::shared_ptr< LookupTableParams<T>> ret = sinLookupTable.lock();
if (!ret) {
ret = std::make_shared<LookupTableParams<T>>();
std::function<double(double)> f = AudioMath::makeFunc_Sin();
// Used to use 4096, but 512 gives about 92db snr, so let's save memory
// working on high purity BasicVCO. move up to 2k to get rid of slight
// High-frequency junk (very, very low);
LookupTable<T>::init(*ret, 2 * 1024, 0, 1, f);
sinLookupTable = ret;
}
return ret;
}
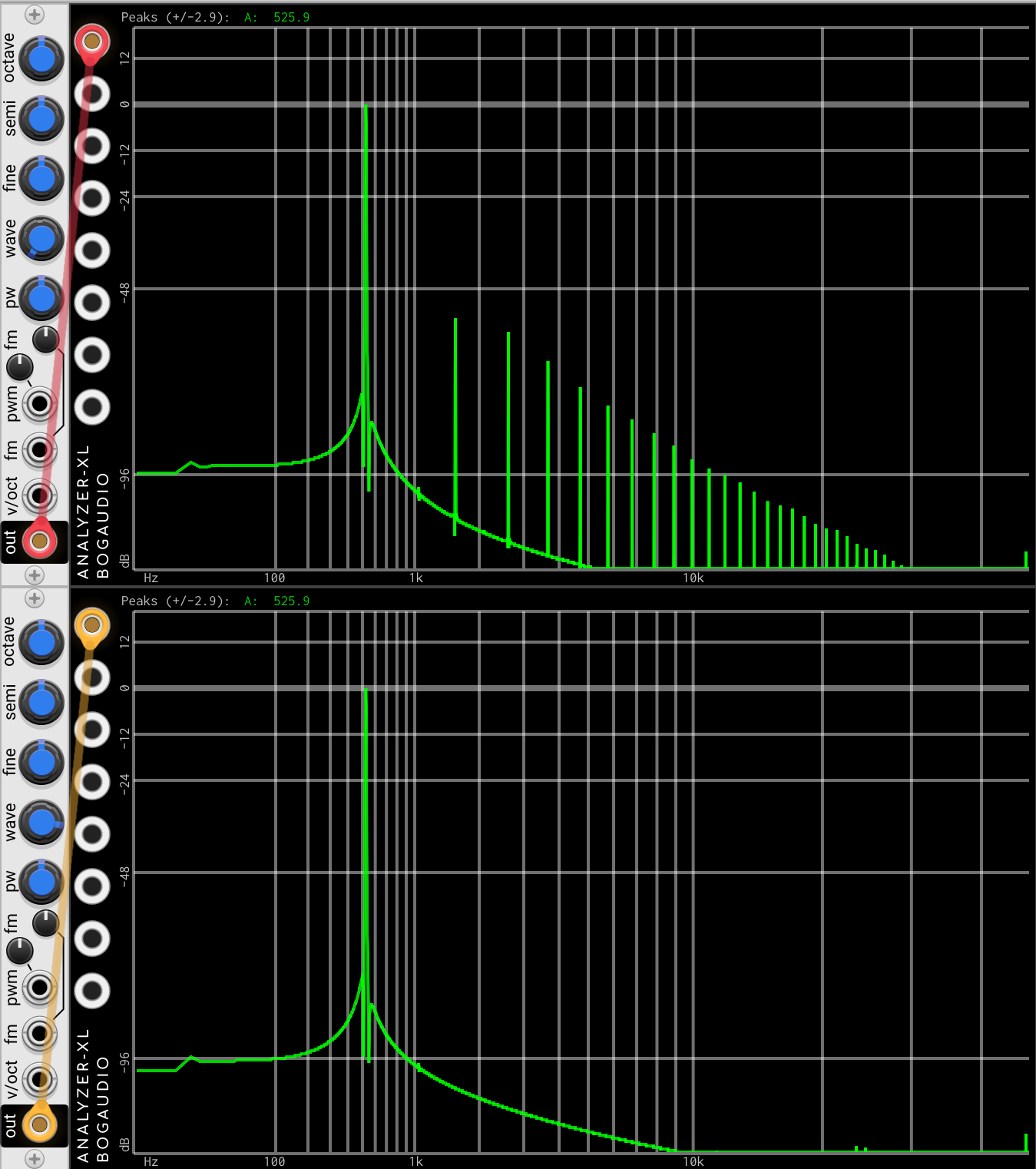
btw, I didn’t use the sin approximation from the VCV library, I wrote my own. The typical sin approximation tries to minimize all errors, but I wanted to minimize the “jump” that you tend to get when your trig approximation wrap around. None the less, check out BasicVCO. Top is the normal sine wave, that uses my SIMD approximation (“sine”), bottom uses the 2k lookup table (“pure sine”). Of course on top the spurious harmonics are super low already as you can see. But I do like to tinker:
As for how good they are, it’s a massive “It depends”. If you know your sample rate and only want to output one frequency, then in theory they’re no different in output at dramatically lower CPU cost. If you need to interpolate through them, it gets tricky. There’s some good tables online, but it’s also pretty trivial to generate your own with python (or matlab, or whatever you like, I guess) - I actually had to do that this week for a class.
I’m pretty sure something odd is going on, and I have noticed this before too. Back when I made LyraeModules I hadn’t noticed the bad Windows performance with Sine until Squinky pointed it out to me and I went to test on Windows. It’s probably the case here again then too- though I don’t think it’s the compiler being different, I think it’s pulling the sine function from a different library with a more sane implemention.
Well, that’s certainly interesting. You say FastTrig is slower on Linux, but I assume that’s relative to without fast-trig on Linux, so I’d be curious to know how Linux compares to Windows outright- probably need to count cycles… though it’s been a hot minute since I’ve tried to do so directly with GDB.
I don’t think so. I haven’t checked, but I suspect the 2.1 times faster with newer GCC is only catching up to the 1.1 times slower of Linux. Especially since using Manjaro (Ahornberg) and Arch (Me) are both the same same GCC package, presumably using GCC 11.2 already. This would align with past, non-scientific experience where VCV seemed to be able to run with a lower buffer size on Linux with more modules before underruns.
I think I recall that VCV itself and all modules in the library are complied using the latest C++ std and GCC available on a ‘stock’ MacOS install, for reasons (?) so if we don’t have control over the compiler anyway using rack::simd might still be the best option for getting at least uniform performance?
Until here it was an interesting journey about optimizing code. For me, the takeaway is to test on all target platforms, if possible.
By rethinking how to optimize the Pink Trombone, I noticed that in Tract::setRestDiameter() the values of t and therefore the values of cos(t) stay the same from call to call as long as no knob or input CV value changes. So this values, or in conclusion, the whole this->restDiameter[] could be cached. Maybe this is an approach for further performance tuning.
I find performance in VCV hard for this reason. Doing useless computation can sometimes be good in the pursuit of consistent performance over good performance. The last thing we’d want is for some one to only occasionally send a new CV value and have that cause an underrun each time, if the audio thread(s) are close to maxxed out. It’s sort of like the same idea in crypto, where you often want to do useless operations to avoid power side channel attacks.
I think it’s the if statement in cos causing branch prediction failures. It might be faster to use division and remainder with some predicates. Also, modern C libraries use a Pade approximant P(x)/Q(x) I think.
Generally the amount/ratio of evaluating of modulation input values (and further processing) can have a lot of effect on performance. Obviously these design choices also affect (expand or restrict) modulation related functionality.
Ideally we would want “realtime” updates for each processing cycle, just in case we might need it. But…this is not always needed. Accurate high resolution timing might not allways be of the essence.
Maybe you would only need none or only low res modulation at some point in time, but high res at some other point in time.
So…maybe optionally enable ‘setting’ or ‘modulating’ of the modulation read/update/refresh rate? Either statically (e.g. via “Context Menu” or “Switch/Selector”) or dynamically (e.g. via Trigger/Gate/Modulation input).
This way you could “simply” set the required update rate(s) as needed/desired. Ideally for each modulation input/target, but could be per module as well.
But…implementing such a “straightforward” concept in itself might be costly (or difficult/impossible). Although the ‘refresh rate’ for such an input could be very low (many, many samples latency could be acceptable).