Ok!
I see it does not support AVX (and neither does VCV), but I can’t find anything definitive about ss2 which we all use.
Sorry, you are absolutely right, I was confused with SSE intrinsics and AVX which is some sort of accelerated matrix operation.
I also found no info relating SSE and Rosetta, but I guess that if it wouldn’t supported Apple had pointed this out beside its compatibility notes…seems that Rack may work on M1 

fingers crossed then, hopefully! ![]()
![]()
We’ll see it next week  (I hope delivery will be not delayed…)
(I hope delivery will be not delayed…)
1 Like
more
and
and
2 Likes


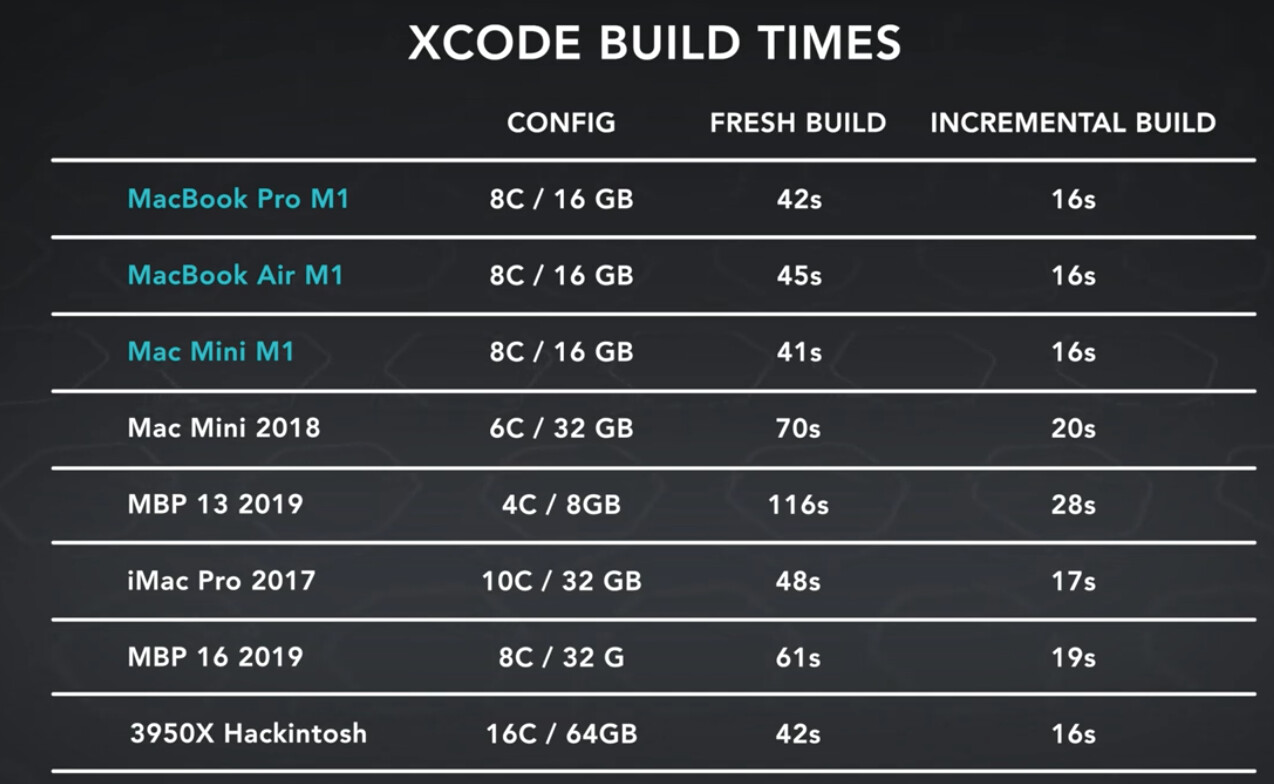
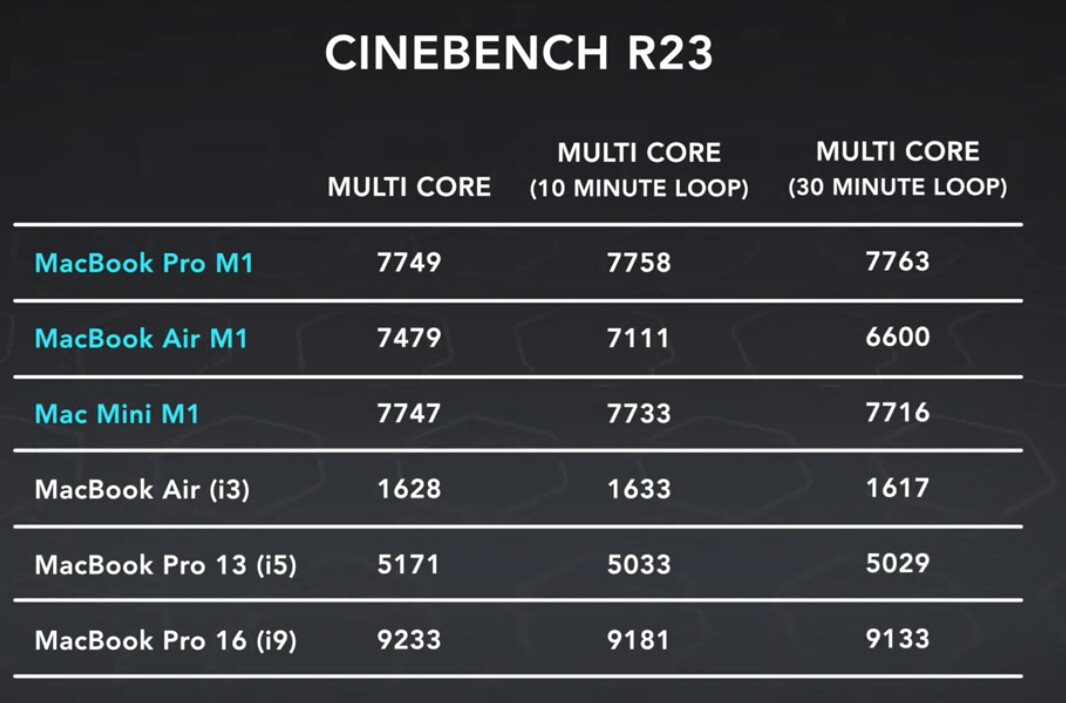
Some info from HN thread
AVX vs AVX off benchmark run for Cinebench from 128bit SSE to 256bit AVX and doubling the ALUs only results in a 10-12% increase in performance
With AVX, Intel increased the size of these registers to 256bit (eight floats) in 2011 and are currently pushing AVX512 doubles the width again (16 floats).
Apple, and ARM in general are limited to 128bit vector registers (though they are plans to increase that in the future)
Cinebench is well known as a benchmark which takes advantage of the 256bit AVX registers, and some people have speculated that Apple’s M1 might be at a significant disadvantage because of this, with just half the ALU thoughput.
But these numbers show that while cinebench gets a notable boost from AVX, it’s not as large as you might think (at least on this workload), allowing the M1’s IPC advantage to shine though. A SIMD is basically controller + ALUs. A wider SIMD gives a better calculation to controller ratio. Fewer instructions decreases pressure on the entire front-end (decoder, caches, reordering complexity, etc). This is more efficient overall if fully utilized.
The downsides are that wide units can affect core clockspeeds (slowing down non-SIMD code too), programmers must optimize their code to use wider and wider units, and some code simply can’t use execution units wider than a certain amount.
Since x86 wants to decrease decode at all costs (it’s very expensive), this approach makes a lot of sense to push for. If you’re doing math on large matrices, then the extra efficiency will make a lot of sense (this is why AVX512 was basically left to workstation and HPC chips).
Apple’s approach gambles that they can overcome the inefficiencies with higher utilization. Their decode penalty isn’t as high which is the key to their strategy. They have literally twice the decode width of x86 (8-wide vs 4-wide – things get murky with x86 combined instructions, but I believe those are somewhat less common today).
In that same matrix code, they’ll have (theoretically) 4x as many instructions for the same work as AVX512 (2x vs AVX2, so we’d expect to see the x86 approach pay off here. In more typical consumer applications, code is more likely to use intermittent vectors of short width. If the full x86 SIMD can’t be used, then the rest is just transistors and power wasted (a very likely reason why AMD still hasn’t gone wider than AVX2).
To keep peak utilization, M1 has a massive instruction window (a bit less than 2x the size as Intel and close to 3x the size of AMD at present). This allows it to look far ahead for SIMD instructions to execute and should help offset the difference in the total number of instructions in SIMD-heavy code too.
Now, there’s a caveat here with SVE. Scalable vector extensions allow the programmer to give a single instruction along with the execution width. The implementation will then have the choice of using a smaller SIMD and executing a lot or a wider SIMD and executing fewer cycles. The M1 has 4 floating point SIMD units that are supposedly identical (except that one has some extra hardware for things like division). They could be allowing these units to gang together into one big SIMD if the vector is wide enough to require it. This is quite a bit closer to the best of both worlds (still have multiple controllers, but lose all the extra instruction pressure).
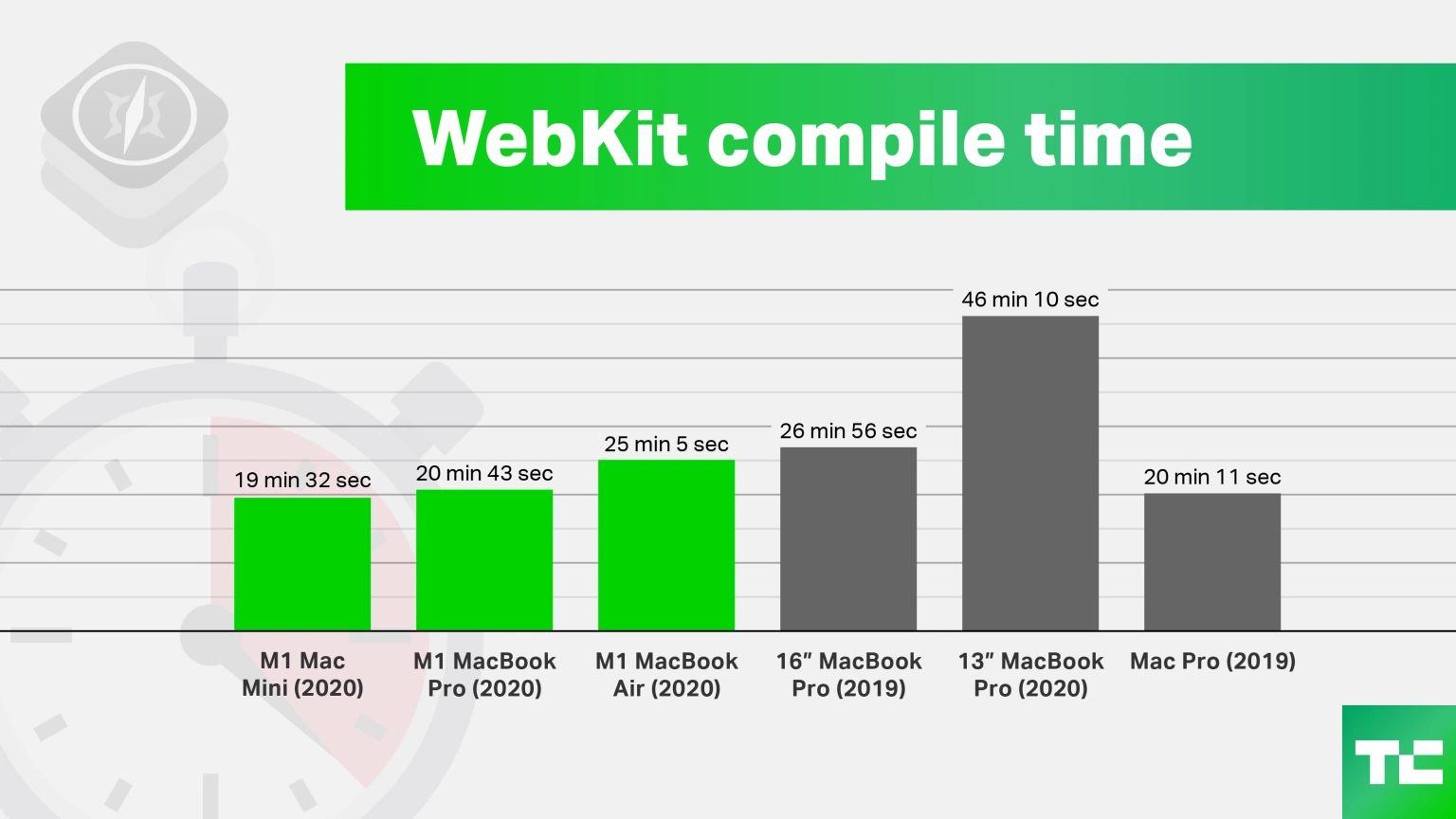
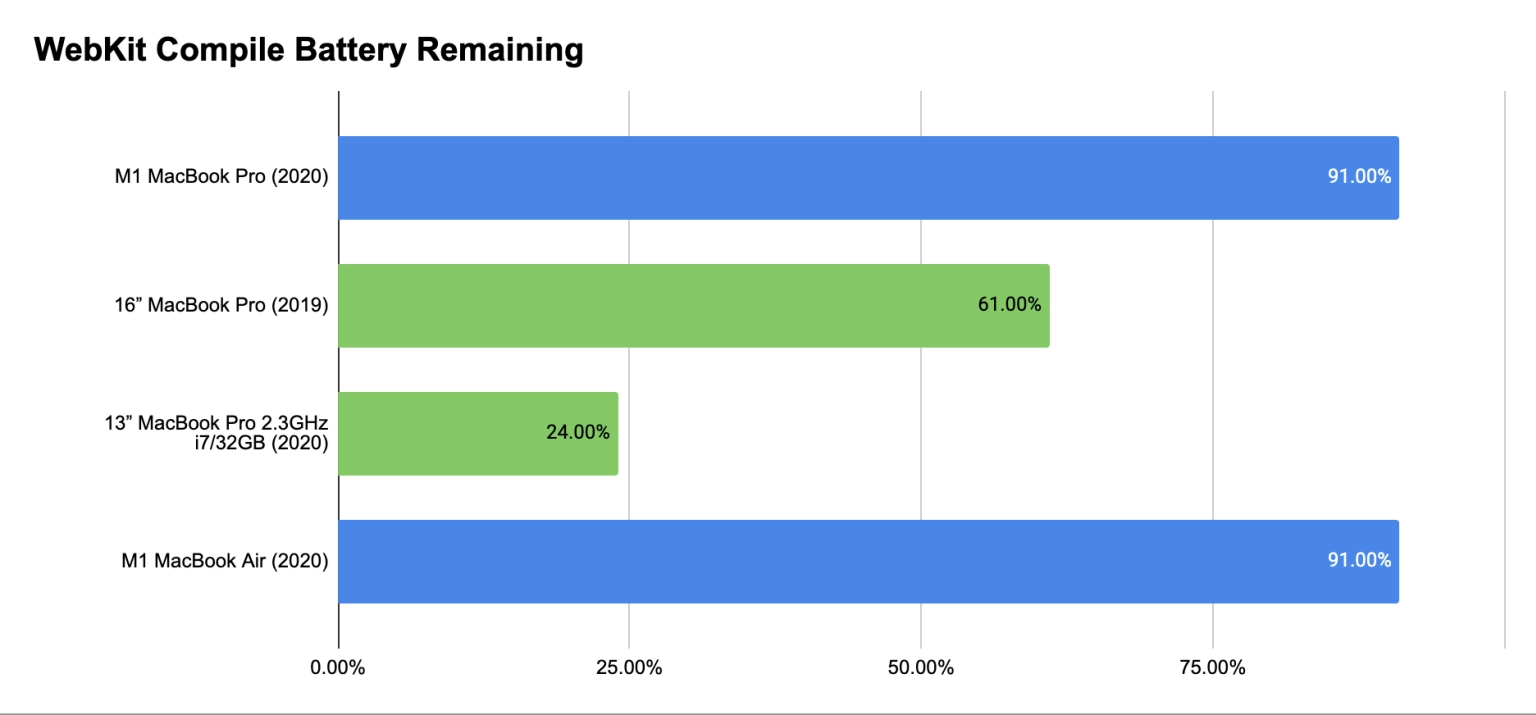
3 Likes
Yeah… so, the first reviews of the 3 first Apple M1 machines are in and they are pretty gushy, but seem fairly serious:
It seems like those machines put my pessimism to shame. Rosetta2 seems to run very well, the inbuilt graphics seem very performant, the M1 runs very cool, and surprisingly they seem to have great single-core performance and might make very good developer machines.
We’ll see… I have ordered a baseconfig Macbook Air M1 for my girlfriend on her birthday and it arrives tomorrow. If it runs Rack with the default patch well for 20 minutes I’ll be impressed. If it runs a medium sized patch well at all I’ll be seriously impressed. I’ll let you know…
Well, it seems Apple might just about pull me back from the brink of leaving them with these machines. The Mini is actually looking attractive to me. If those chips can run Rack well, with those new onboard graphics it’s quite interesting.
5 Likes
Yeah, the point isn’t about how much is speeds it up. with sse2, afaik, many, many plugins use it, and no-one codes in a fallback path. Once VCV allows AVX (if they do), then people will use it with no fall back. So it’s not “slows down 10%”, it’s “does not run at all”.
I think AVX currently isn’t used anywhere and SSE intrinsics should be done by Rosetta 2 fine, so I guess the new machines will “translate” VCV Rack just fine and still very performant.
Unfortunately I have to wait until November 30th to get my MacMini due to delivering problems…
I will then give a detailed report about VCV Rack and Rack development on M1 under BigSur… 
4 Likes
i just had the chance to quickly test vcvrack on the new macbook air of a friend and can report that the intel version seems to run flawless on the m1 mac and cpu usage is quite low so it should be useable as it is already and there is no real pressure to get it working natively … i must admit i’m pretty impressed, looks like they really found their way around the laws of physics
9 Likes
Thanks for the report!
Can’t wait to get my MacMini 
1 Like
The machine just arrived at the store  So I will do a deep review on it today… (and night!)
So I will do a deep review on it today… (and night!) 
6 Likes
The only thing that interests me with these machines is how they are supposed to allow iPad apps to run alongside Mac apps like Logic. I’ve already invested a fair bit in iPad apps so hoping they don’t try to get people to pay twice to use the same app on both machines.
It’s down to each developer. The developers individually decide whether their iOS binaries are allowed to be distributed on the Mac App Store. The initial reviews of this feature from Ars Technica and Gruber both have a kind of “eh” tinge to it, since all of these apps were designed for touch and are now being driven with a mouse that emulates touch gestures.
Sure I get it’d be beneficial in the long run to have full touch support, but I’d rather lose something there short term to be able to incorporate apps like Moog System 15 and Patterning 2 in a fully fledged desktop DAW.
a sort of benchmark test or something…

How much Dexters can you run? ![]() This is on a Mac Mini M1 w 8gb of Ram, the max I can load before audio starts to crackle. 44.1, threads set to 2.
This is on a Mac Mini M1 w 8gb of Ram, the max I can load before audio starts to crackle. 44.1, threads set to 2.
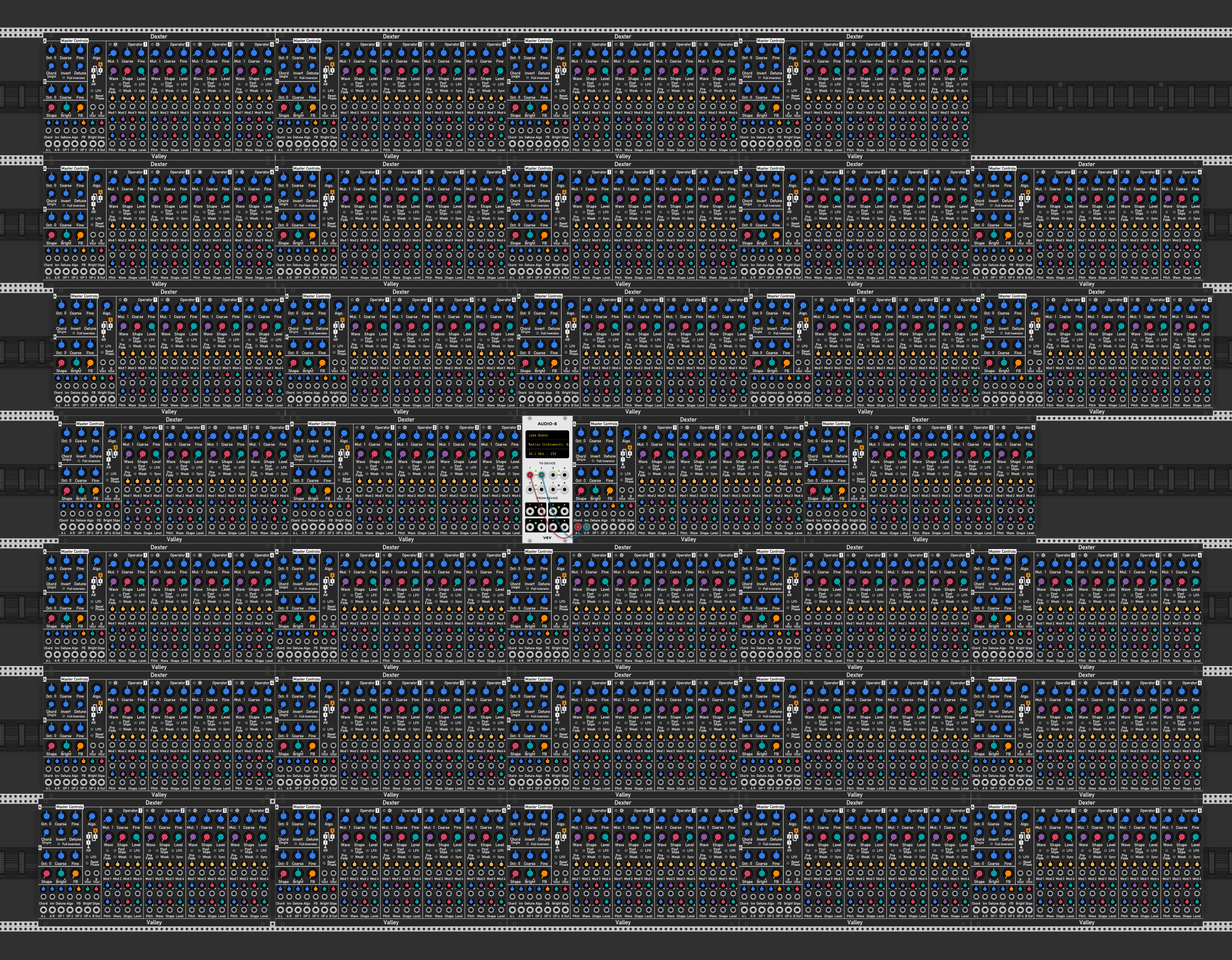
10 Likes
Keep em coming people!

All the benchmarkings with the usual application are not worthy,
i wanna see those M1’s loaded with monstreous VCV patches muahahaha 
5 Likes